
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy.stats import chi2_contingency
from ucimlrepo import fetch_ucirepoIn [1]:
In [2]:
# Dataset.
ds = fetch_ucirepo(id=697)
# DataFrame.
df = ds.data.original1 Introdução
A evasão universitária é um fenômeno complexo que impacta tanto as instituições de ensino quanto a trajetória profissional dos estudantes. Segundo o modelo de integração estudantil de Tinto (1975), a decisão de abandonar o curso raramente é isolada, sendo fruto de uma interação dinâmica entre as características do indivíduo e o ambiente acadêmico.
Compreender esses fatores é fundamental, especialmente em um cenário onde as taxas de desistência no ensino superior permanecem alarmantes. No Brasil, por exemplo, dados recentes apontam que a taxa de evasão acumulada pode ultrapassar 50% em diversos cursos, gerando grandes perdas sociais e econômicas (INEP, 2022).
Neste trabalho, investigamos o problema da desistência no ensino superior utilizando dados reais. A análise se justifica pela necessidade de identificar padrões ocultos que possam sinalizar, precocemente, estudantes em situação de risco.
Para isso, utilizamos o conjunto de dados Predict Students’ Dropout and Academic Success, disponível no UCI Machine Learning Repository (Martins et al., 2021). Os dados provêm de uma instituição de ensino superior (Politécnico de Portalegre, Portugal) e englobam diversas dimensões da vida estudantil, incluindo fatores demográficos, socioeconômicos e de desempenho acadêmico prévio. A natureza dos dados é mista, contendo variáveis qualitativas (como estado civil e curso) e quantitativas (como notas e idade), permitindo uma análise estatística rica e multifacetada.
2 Objetivo
O objetivo principal deste trabalho é aplicar técnicas de estatística descritiva para caracterizar o perfil dos estudantes e identificar variáveis potencialmente associadas à evasão escolar.
Para alcançar este propósito, definiram-se os seguintes objetivos específicos:
- Resumir e Organizar: Sintetizar as variáveis quantitativas do conjunto de dados, calculando medidas de tendência central (média, mediana) e dispersão (desvio padrão) para as notas de qualificação prévia.
- Visualizar: Construir representações gráficas, como histogramas e boxplots, para facilitar a interpretação da distribuição das idades e notas dos alunos.
- Identificar Anomalias: Detectar a presença de outliers (valores atípicos) nas notas de ingresso, investigando a existência de grupos com desempenho discrepante da maioria.
- Caracterizar: Descrever a natureza das variáveis disponíveis no banco de dados, classificando-as conforme seus tipos e escalas para fundamentar a escolha das técnicas estatísticas aplicadas.
- Analizar: Buscar um fator em potencial que pode influenciar na desistência dos discentes, assim auxiliando a pesquisa de métodos combativos da desistência estudantil.
3 Materiais e Métodos
O dataset utilizado, Predict Students’ Dropout and Academic Success tem como origem o Instituto Politécnico de Portalegre (PP), Portugal (Martins et al., 2021, p. 167). Os dados foram coletados desde 2008 até 2019 (Martins et al., 2021, p. 168). Foi selecionado devido à relevância acadêmia e por não ter valores faltando em nenhuma das colunas, facilitando o processo de tratamento para a análise dos dados. A tabela a seguir detalha as variáveis encontradas no dataset, e seus tipos.
In [3]:
def classificar_variavel(coluna):
"""
Classifica o tipo de variável e escala, obedecendo exceções.
"""
dtype = coluna.dtype
n_unicos = coluna.nunique()
nome = coluna.name
excecoes = [
'Nacionality',
"Mother's occupation",
"Father's occupation"
]
if dtype == 'string':
return 'Qualitativa', 'Nominal'
if np.issubdtype(dtype, np.floating):
return 'Quantitativa', 'Contínua'
if np.issubdtype(dtype, np.integer):
# Se tiver menos de 20 valores únicos, então é uma categoria
# (Estado Civil, Curso, Idade...)
if (nome in excecoes) or (n_unicos < 20):
return 'Qualitativa', 'Nominal'
else:
return 'Qualitativa', 'Discreta'
return 'Outro', 'Outro'
dados_auto = []
for index, col_name in enumerate(df.columns):
tipo, escala = classificar_variavel(df[col_name])
dados_auto.append({
'Variável': col_name,
'Descrição': ds.variables['description'][index],
'Tipo inferido': tipo,
'Escala Inferida': escala
})
pd.DataFrame(dados_auto)In [3]:
| Variável | Descrição | Tipo inferido | Escala Inferida | |
|---|---|---|---|---|
| 0 | Marital Status | 1 – single 2 – married 3 – widower 4 – divorce... | Qualitativa | Nominal |
| 1 | Application mode | 1 - 1st phase - general contingent 2 - Ordinan... | Qualitativa | Nominal |
| 2 | Application order | Application order (between 0 - first choice; a... | Qualitativa | Nominal |
| 3 | Course | 33 - Biofuel Production Technologies 171 - Ani... | Qualitativa | Nominal |
| 4 | Daytime/evening attendance | 1 – daytime 0 - evening | Qualitativa | Nominal |
| 5 | Previous qualification | 1 - Secondary education 2 - Higher education -... | Qualitativa | Nominal |
| 6 | Previous qualification (grade) | Grade of previous qualification (between 0 and... | Quantitativa | Contínua |
| 7 | Nacionality | 1 - Portuguese; 2 - German; 6 - Spanish; 11 - ... | Qualitativa | Nominal |
| 8 | Mother's qualification | 1 - Secondary Education - 12th Year of Schooli... | Qualitativa | Discreta |
| 9 | Father's qualification | 1 - Secondary Education - 12th Year of Schooli... | Qualitativa | Discreta |
| 10 | Mother's occupation | 0 - Student 1 - Representatives of the Legisla... | Qualitativa | Nominal |
| 11 | Father's occupation | 0 - Student 1 - Representatives of the Legisla... | Qualitativa | Nominal |
| 12 | Admission grade | Admission grade (between 0 and 200) | Quantitativa | Contínua |
| 13 | Displaced | 1 – yes 0 – no | Qualitativa | Nominal |
| 14 | Educational special needs | 1 – yes 0 – no | Qualitativa | Nominal |
| 15 | Debtor | 1 – yes 0 – no | Qualitativa | Nominal |
| 16 | Tuition fees up to date | 1 – yes 0 – no | Qualitativa | Nominal |
| 17 | Gender | 1 – male 0 – female | Qualitativa | Nominal |
| 18 | Scholarship holder | 1 – yes 0 – no | Qualitativa | Nominal |
| 19 | Age at enrollment | Age of studend at enrollment | Qualitativa | Discreta |
| 20 | International | 1 – yes 0 – no | Qualitativa | Nominal |
| 21 | Curricular units 1st sem (credited) | Number of curricular units credited in the 1st... | Qualitativa | Discreta |
| 22 | Curricular units 1st sem (enrolled) | Number of curricular units enrolled in the 1st... | Qualitativa | Discreta |
| 23 | Curricular units 1st sem (evaluations) | Number of evaluations to curricular units in t... | Qualitativa | Discreta |
| 24 | Curricular units 1st sem (approved) | Number of curricular units approved in the 1st... | Qualitativa | Discreta |
| 25 | Curricular units 1st sem (grade) | Grade average in the 1st semester (between 0 a... | Quantitativa | Contínua |
| 26 | Curricular units 1st sem (without evaluations) | Number of curricular units without evalutions ... | Qualitativa | Nominal |
| 27 | Curricular units 2nd sem (credited) | Number of curricular units credited in the 2nd... | Qualitativa | Nominal |
| 28 | Curricular units 2nd sem (enrolled) | Number of curricular units enrolled in the 2nd... | Qualitativa | Discreta |
| 29 | Curricular units 2nd sem (evaluations) | Number of evaluations to curricular units in t... | Qualitativa | Discreta |
| 30 | Curricular units 2nd sem (approved) | Number of curricular units approved in the 2nd... | Qualitativa | Discreta |
| 31 | Curricular units 2nd sem (grade) | Grade average in the 2nd semester (between 0 a... | Quantitativa | Contínua |
| 32 | Curricular units 2nd sem (without evaluations) | Number of curricular units without evalutions ... | Qualitativa | Nominal |
| 33 | Unemployment rate | Unemployment rate (%) | Quantitativa | Contínua |
| 34 | Inflation rate | Inflation rate (%) | Quantitativa | Contínua |
| 35 | GDP | GDP | Quantitativa | Contínua |
| 36 | Target | Target. The problem is formulated as a three c... | Qualitativa | Nominal |
Como medida descritiva, foi utilizada principalmente a dispersão para análise, devido a sua capacidade de destacar potenciais outliers, que no caso desse estudo, seriam estudantes de baixo e alto rendimento acadêmico.
Como métodos estatísticos, foram aplicadas as medidas de tendência central para a análise das notas de qualificações prévias dos alunos. As medidas de tendência central incluem:
- Média
Dada por:
\[ \overline{X} = \frac{\sum_{i=1}^{N} x_{i}}{N} \]
Onde:
- \(x_{i}\)
- Valor da observação \(i\).
- \(N\)
- Número de observações da amostra.
- Mediana
Dada por:
\[ M = \begin{cases} \frac{N}{2}, & N = 2k \\ \frac{N + 1}{2}, & N = 2k + 1 \end{cases} \]
Onde:
- \(N\)
- Número de observações da amostra.
- Moda
Geralmente é pensada como a observação de maior valor, mas podemos usar a Fórmula de King para calculá-la:
\[ M_{o} = L_{i} + \frac{n_{i} + 1}{n_{i} - 1 + n_{i} + 1} \cdot a_{i} \]
Onde:
- \(L_{i}\)
- Limite inferior da classe modal.
- \(n_{i} + 1\)
- Frequência absoluta da clase posterior à classe modal.
- \(n_{i} - 1\)
- Frequência absoluta da classe anterior à classe modal.
- \(a_{i}\)
- Amplitude da classe modal.
Além das medidas de tendência central, foi aplicada a medida de dispersão desvio padrão para identificar a variabilidade dos dados. Ela é dada por:
\[ DP = \sqrt{\frac{\sum_{i = 1}^{N} (x_{i} - \overline{X})^{2}}{N}} \]
Onde:
- \(x_{i}\)
- Valor da observação \(i\).
- \(\overline{X}\)
- Média das observações da amostra.
- \(N\)
- Número de observações da amostra.
Para o teste de hipótese foi utilizado o Teste Qui-Quadrado de Independência (Pearson, 1900).
- Teste Qui-Quadrado de Independência
Teste estatístico aplicado a dados qualitativos para avaliar a probabilidade da diferença entre conjuntos surgiu por chance. É dado por:
\[ \chi^{2} = \sum^{n}_{i = 1} \frac{(O_{i} - E_{i})^{2}}{E_{i}} \]
Onde:
- \(O_{i}\)
- Número de observações do tipo \(i\).
- \(n\)
- Número de obsevações da amostra.
- \(E_{i}\)
- Valor esperado de \(i\).
Para o processamento e análise dos dados mediante gráficos, foi utilizada a linguagem de programação Python (Python Software Foundation, 2025). A tabela a seguir detalha as bibliotecas usadas, e suas utilidades.
| Biblioteca | Função |
|---|---|
matplotlib («Matplotlib», [S.d.]) |
Gerar gráficos a partir dos dados. |
pandas (Pandas Team, 2026) |
Manipular o dataset. |
ucimlrepo («Ucimlrepo», [S.d.]) |
Baixar o dataset pronto para manipulação do UCI Machine Learning Repository. |
numpy (Harris et al., 2020) |
Análise de tipos de dados. |
scipy (Virtanen et al., 2020) |
Cálculo do Teste Qui-Quadrado de Independência (Pearson, 1900). |
4 Resultados
In [4]:
# Calculando as estatísticas
descritiva = df['Previous qualification (grade)'].describe()
# Mostrando a tabela formatada.
descritiva.to_frame().style.format("{:.2f}")In [4]:
| Previous qualification (grade) | |
|---|---|
| count | 4424.00 |
| mean | 132.61 |
| std | 13.19 |
| min | 95.00 |
| 25% | 125.00 |
| 50% | 133.10 |
| 75% | 140.00 |
| max | 190.00 |
In [5]:
plt.figure(figsize=(8, 4))
plt.boxplot(df['Previous qualification (grade)'], vert=False, patch_artist=True)
plt.title('Boxplot: Notas de Qualificação Prévia')
plt.xlabel('Nota')
plt.grid(True, linestyle='--', alpha=0.6)
plt.show()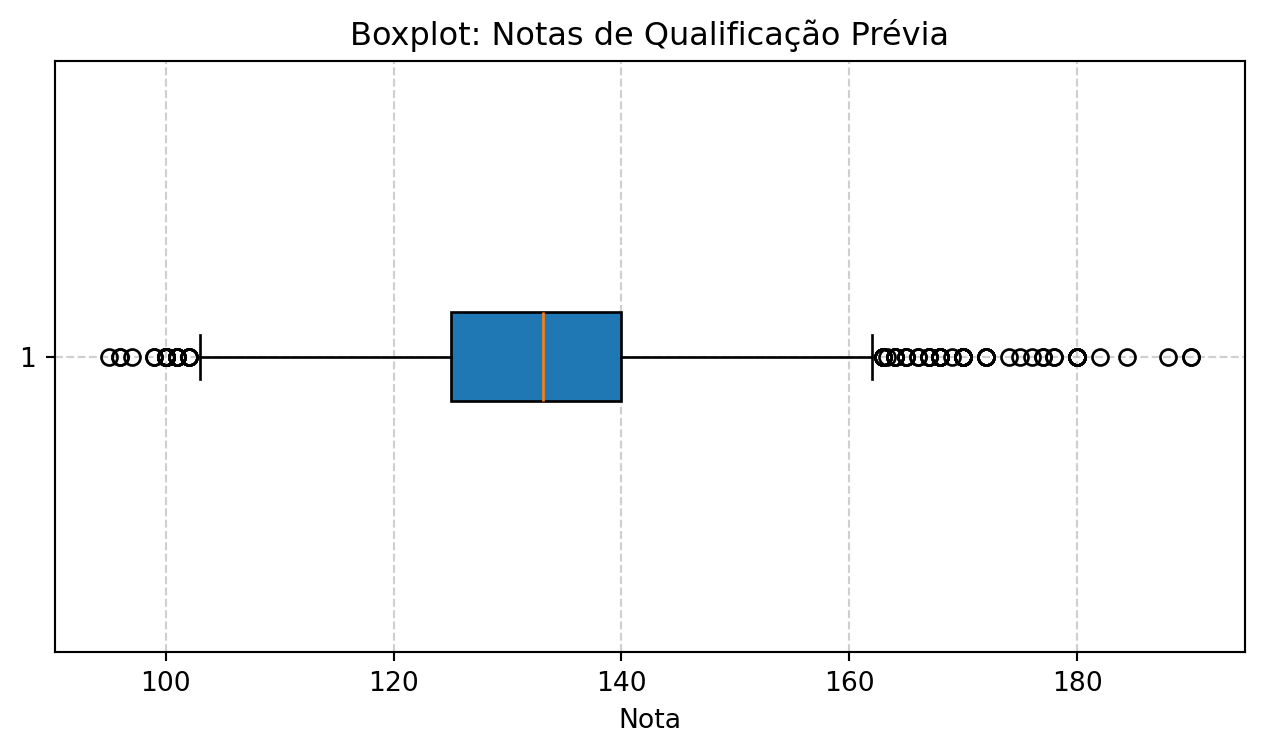
In [6]:
df['Situacao'] = df['Target'].apply(lambda x: 'Dropout' if x == 'Dropout' else 'Cursando/Formado')
grupos = ['Dropout', 'Cursando/Formado']
dados_plot = []
for grupo in grupos:
filtro = df['Situacao'] == grupo
valores = df.loc[filtro, 'Curricular units 1st sem (grade)']
valores_limpos = valores[(valores >= 0) & (valores <= 20)]
dados_plot.append(valores_limpos)
plt.figure(figsize=(10, 6))
plt.boxplot(dados_plot, tick_labels=grupos, patch_artist=True, vert=False)
plt.title('Notas do primeiro Semestre por Situação Final')
plt.xlabel('Nota Média (0-20)')
plt.ylabel('Situação Final')
plt.grid(True, linestyle='--', alpha=0.3)
plt.show()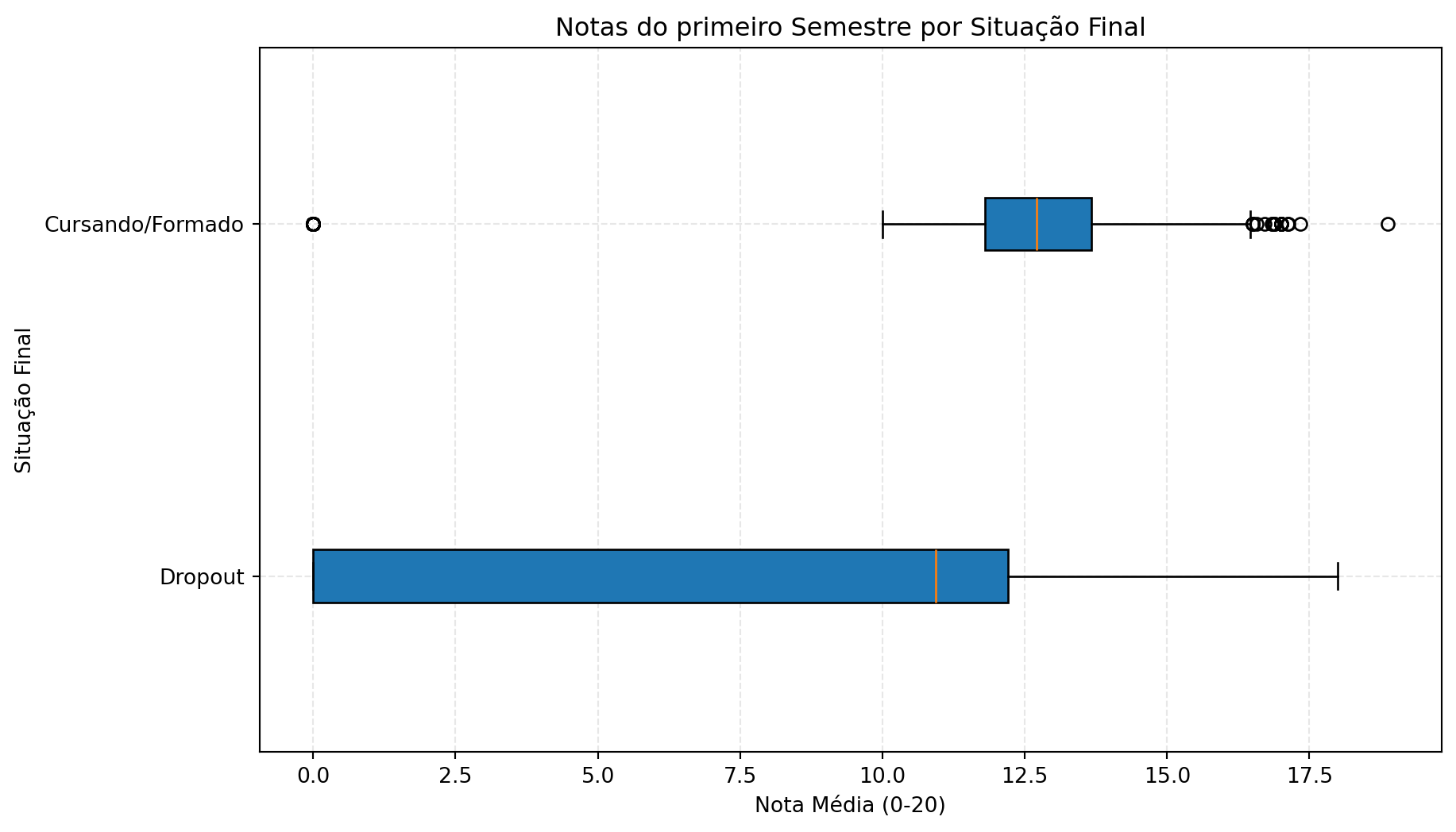
In [7]:
com_divida = df[df['Debtor'] == 1]
sem_divida = df[df['Debtor'] == 0]
taxa_com_divida = (com_divida['Target'] == 'Dropout').mean() * 100
taxa_sem_divida = (sem_divida['Target'] == 'Dropout').mean() * 100
categorias = ['Sem Dívida', 'Com Dívida']
valores = [taxa_sem_divida, taxa_com_divida]
plt.figure(figsize=(8, 6))
plt.bar(categorias, valores, color=['blue', 'red'])
plt.title('Taxa de Evasão por Situação de Dívida')
plt.ylabel('% de Evasão')
plt.ylim(0, 100)
plt.show()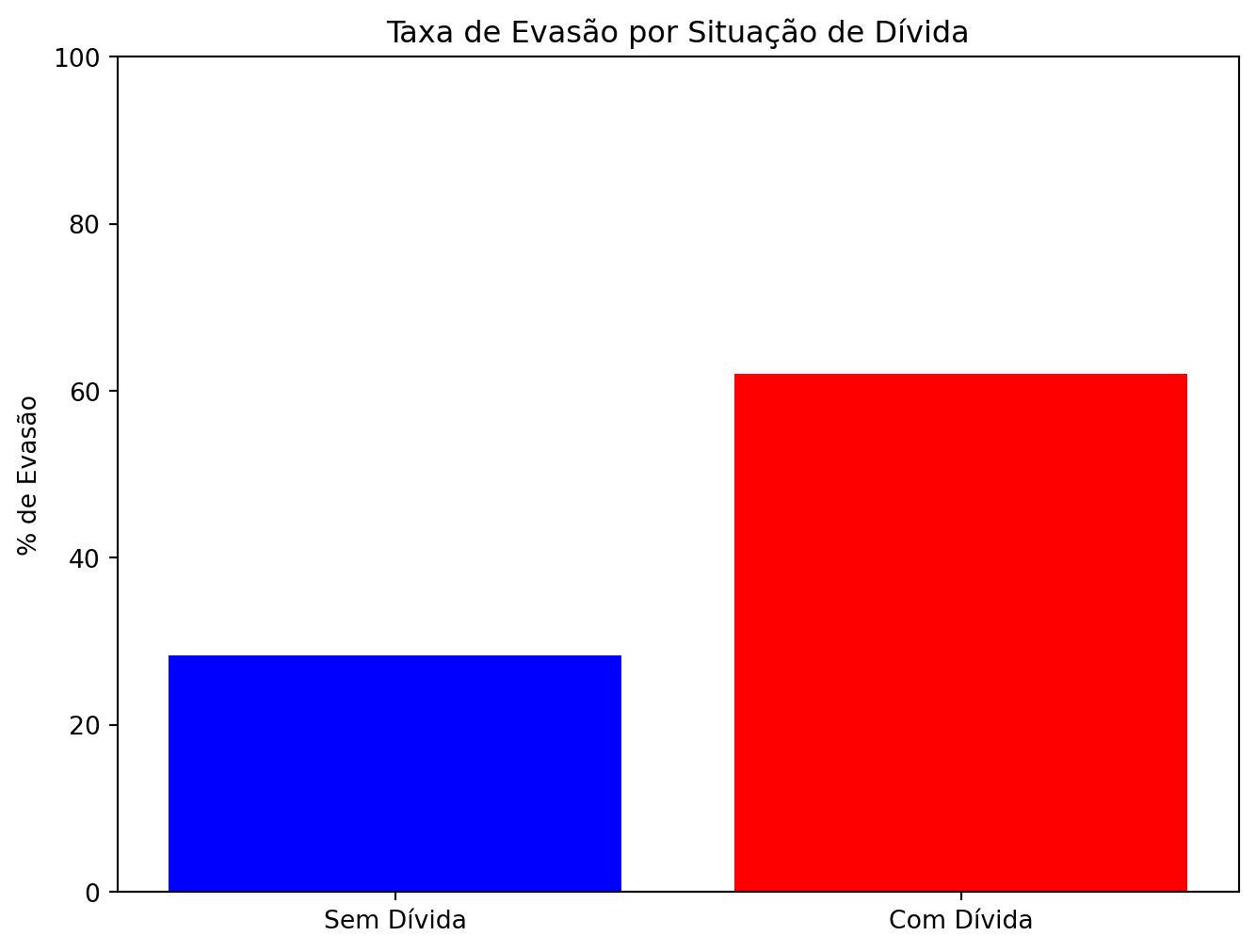
4.1 Análise dos Resultados
Com base na Tabela 3, observamos que a nota média de qualificação prévia dos alunos é de aproximadamente 132,6 pontos, com uma mediana muito próxima (133,1), o que indica uma distribuição relativamente simétrica.
Entretanto, o Boxplot (Figura 1) revela a presença clara de outliers (valores atípicos). Notamos um grupo de alunos com notas excepcionalmente altas (acima de 160) e outro com notas muito baixas (abaixo de 100). Esses pontos discrepantes sugerem que o nível de preparo prévio dos alunos é bastante heterogêneo.
4.2 Análise de Hipótese
In [8]:
tabela_contingencia = pd.crosstab(df['Debtor'], df['Target'])
# Teste Qui-Quadrado.
chi2, p_valor, graus_liberdade, frequencias_esperadas = chi2_contingency(tabela_contingencia)Das figuras acima, uma das mais chamativas é o gráfico de barras Figura 3, pois parece indicar uma relação entre dívida e persistência. Para análise de correlação, podemos investigar a seguinte hipótese nula (\(H_{0}\)): “Estar em dívida não afeta a desistência do curso”. Mediante um Teste Qui-Quadrado de Independência, descobrimos que o valor-p de \(H_{0}\) é aproximadamente 4.858552123231672e-57, que é menor que 5% (0.05). Logo, podemos rejeitar a hipótese nula, o que pode indicar uma hipótese alternativa (\(H_{1}\)) de que estar individado afeta a desistência do curso.
5 Conclusão
A análise estatística descritiva realizada sobre o banco de dados Predict Students’ Dropout and Academic Success permitiu uma compreensão detalhada da dinâmica de evasão na instituição estudada. O perfil acadêmico de ingresso, sintetizado pela nota média de 132,6 pontos, revela um cenário de equilíbrio central, mas que é fortemente impactado pela presença de outliers (valores atípicos) em ambas as extremidades da escala.
5.1 A Natureza dos Outliers
A existência de tantos pontos discrepantes — alunos com notas excepcionalmente altas (acima de 160) e outros com notas muito baixas (abaixo de 100) — sugere uma heterogeneidade estrutural no preparo prévio dos discentes. Tecnicamente, esses outliers ocorrem por dois motivos principais:
- Diferenças na Formação Base: Alunos provenientes de contextos educacionais de excelência elevam o limite superior, enquanto aqueles com lacunas profundas na formação básica formam a cauda inferior da distribuição.
- Diversidade de Perfil de Ingresso: Como o dataset engloba diversas idades e origens, os outliers podem representar alunos que retornaram aos estudos após longo período ou profissionais já graduados em outras áreas, cujas notas de qualificação não seguem a tendência da maioria “recém-saída” do ensino secundário.
5.2 Padrões e Implicações Práticas
Os resultados visuais obtidos através dos boxplots e gráficos de barras facilitam a identificação de padrões de risco. Observou-se, por exemplo, que a variável “Dívida Ativa” é um divisor de águas: a taxa de evasão entre alunos com dívidas é significativamente superior à dos alunos não individados. Isso indica que a evasão não é um fenômeno puramente acadêmico, mas também econômico e social.
Além disso, a comparação das notas do primeiro semestre mostrou que os alunos que evadiram (Dropouts) tendem a apresentar uma concentração de notas na faixa inferior logo nos primeiros meses. Isso prova que o insucesso inicial funciona como um “sintoma” precoce, permitindo que a universidade identifique o aluno em risco antes mesmo dele abandonar o curso de fato.
Ao correlacionar as dimensões analisadas, observa-se a formação de um “efeito cascata” que potencializa a vulnerabilidade do discente. O aluno que ingressa com notas de qualificação mais baixas (preparo prévio deficitário) frequentemente enfrenta maiores obstáculos pedagógicos, o que se traduz em notas insatisfatórias logo no primeiro semestre. Quando esse quadro de dificuldade acadêmica é agravado pela situação de endividamento, a evasão deixa de ser uma possibilidade e torna-se um desfecho provável. A pressão financeira força o estudante a priorizar atividades remuneradas em detrimento do tempo de estudo, impedindo a recuperação de suas notas e criando um ciclo onde a insuficiência acadêmica e a fragilidade econômica se retroalimentam. Portanto, a análise revela que o risco de desistência não é fruto de um evento isolado, mas da convergência entre um histórico escolar prévio heterogêneo, um desempenho inicial abaixo da média e a barreira socioeconômica da dívida ativa.
Em suma, este trabalho cumpriu o objetivo de resumir e organizar os dados, estabelecendo uma base empírica sólida para que a instituição possa validar a qualidade de suas estratégias de retenção e orientar futuras decisões metodológicas mais complexas.
5.3 Teste de Hipótese
Mediante análise do gráfico de barras (Figura 3) e execução do teste de hipótese nula, observa-se a dívida como um importante fator na desistência de um estudante. De fato, dívida é um grande fator de estresse (Dodamani, 2024), o que pode desestabilizar o discente.
6 Relato Pessoal
6.1 Caio Aloisio Andrade Silva
O desenvolvimento deste projeto foi uma experiência muito positiva, apesar de alguns desafios. Tive algumas dificuldades pontuais na execução do código e na configuração do ambiente, especialmente o Pandas ao fluxo ao usar o Quarto (Posit team, 2026) do trabalho, mas com ajuda do grupo foi possível passar por cima desse empecilho. Achei especialmente interessante que consegui aplicar conhecimento que antes havia usado apenas em projetos pessoais em um contexto acadêmico e avaliativo. O trabalho em grupo também foi um ponto forte, com boa comunicação entre os integrantes, e o projeto contribuiu para que eu enxergasse a estatística para além de uma disciplina do curso, mostrando sua relação com a área em que pretendo atuar.
6.2 Gabriel Santos de Souza
Já havia previamente trabalhado com Python (Python Software Foundation, 2025) e CSV (Shafranovich, 2005) na disciplina Métodos e Técnicas de Pesquisa para Computação (MTPC) então, em quesito de linguagem, não tive complicação.
A novidade foi mexer com o Pandas (Pandas Team, 2026), Matplotlib («Matplotlib», [S.d.]) e o NumPy (Harris et al., 2020), pois em MTPC eu utilizei a biblioteca Polars («Polars», [S.d.]) para análise dos dados e o Altair (VanderPlas et al., 2018) para geração dos gráficos. Foi também uma ótima oportunidade de experimentar o Quarto (Allaire et al., 2026) como sucessor do R Markdown (Rmarkdown, 2025).
Em relação aos dados em si, achei interessante como justificativas socioeconômicas se aplicam independentemente do país.
6.3 Lucca Pedreira Dultra
Fazer parte desta análise trouxe muito aprendizado. Tive o privilégio de acompanhar uma equipe tão competente e capacitada, assumindo uma postura mais observadora que me permitiu absorver grande conhecimento através das discussões e soluções adotadas.
Minha familiaridade prévia com Python (Python Software Foundation, 2025) facilitou a compreensão lógica do processamento dos dados. Já o Quarto (Posit team, 2026) foi uma novidade interessante de se observar na prática.
Embora estatística não seja o foco da minha área, foi excelente notar sua forte proximidade com a computação. Entender como a programação consegue extrair fatores socioeconômicos dos dados foi enriquecedor. Sou grato à dedicação dos colegas, que garantiram a excelência deste trabalho.
6.4 Tarcisio Almeida Mascarenhas
Uma das dificuldades que tive foi a de executar o código, tive alguns problemas com o Python (Python Software Foundation, 2025) no R Studio (Posit team, 2026), mas consegui resolver depois de algum tempo. Outra dificuldade seria escolher exatamente quais parâmetros usar dentre todos que existem no banco de dados já que uma grande parte deles se complementam entre si, então escolher quais filtrar para podermos provar o nosso ponto sobre o assunto foi bastante interessante de se pensar.
Das novidades, uma delas foi mexer com Python (Python Software Foundation, 2025) e o R Studio (Posit team, 2026), coisa que eu nunca tinha feito e achei bastante interessante a sinergia entre os dois, e a possibilidade de criar documentos como esse sem precisar ficar mudando de aplicativo durante a criação foi bem interessante, também achei bem legal a forma como a estatística e o senso comum andaram lado a lado nesse trabalho mostrando assim que ela também serve para provarmos aquilo que já sabemos de forma empírica, porém não temos dados para comprovar. Além disso, o fato das justificativas socioeconômicas se aplicarem tanto ao Brasil quanto a Portugal, países completamente diferentes em cultura, geografia, economia e desenvolvimento demonstra a possibilidade da situação analisada ser igual para o mundo todo.
6.5 Renato Vasconcelos Campos Filho
A experiência de desenvolver este projeto foi marcada por um contraste entre o desafio instrumental e a satisfação analítica. A principal dificuldade que enfrentei concentrou-se na utilização das ferramentas, especificamente na gestão de ambientes e bibliotecas do Python (Python Software Foundation, 2025) e na renderização do documento final com o Quarto (Posit team, 2026). A curva de aprendizado para configurar as dependências corretamente e integrar o código à narrativa textual foi mais íngreme do que eu esperava.
Apesar dos obstáculos técnicos com a linguagem de programação, o trabalho com os métodos estatísticos foi o ponto alto da atividade. Foi muito gratificante aplicar a teoria na prática e ver como a estatística oferece ferramentas robustas para interpretar a realidade dos dados. A complexidade do código acabou servindo para valorizar ainda mais os resultados obtidos, reforçando a importância da persistência técnica para se alcançar uma análise de dados fundamentada.
Referências
ALLAIRE, J. J. et al. Quarto. Posit Software, PBC, 16 jan. 2026. Disponível em: <https://quarto.org>
DODAMANI, Sachi. The Multifaceted Impact of Financial Stress on Physiological, Psychological Well-being, and Success: A Comprehensive Review and Strategic Interventions. Disponível em: <https://www.preprints.org/manuscript/202411.1862>. Acesso em: 22 fev. 2026.
EDITORCONFIG TEAM. EditorConfig: A file format and collection of text editor plugins for maintaining consistent coding styles. Disponível em: <https://editorconfig.org>. Acesso em: 25 jan. 2026.
GITHUB, INC. GitHub. Disponível em: <https://github.com>. Acesso em: 25 jan. 2026.
HARRIS, Charles R. et al. Array programming with NumPy. Nature, v. 585, n. 7825, p. 357–362, set. 2020.
INEP. Censo da Educação Superior 2021: divulgação dos resultados. BrasíliaInstituto Nacional de Estudos e Pesquisas Educacionais Anísio Teixeira, 2022. Disponível em: <https://www.gov.br/inep/pt-br>
MARTINS, Mónica V. et al. Early Prediction of Student’s Performance in Higher Education: A Case Study. Em: ROCHA, Álvaro et al. (Eds.). Trends and Applications in Information Systems and Technologies. Cham: Springer International Publishing, 2021. v. 1365 p. 166–175.
Matplotlib: Python Plotting Package., [S.d.]. Disponível em: <https://matplotlib.org>. Acesso em: 28 jan. 2026
PANDAS TEAM. Pandas-Dev/Pandas: Pandas. Zenodo, jan. 2026. Disponível em: <https://doi.org/10.5281/zenodo.18328522>
PEARSON, Karl. X. On the Criterion That a given System of Deviations from the Probable in the Case of a Correlated System of Variables Is Such That It Can Be Reasonably Supposed to Have Arisen from Random Sampling. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, v. 50, n. 302, p. 157–175, jul. 1900.
Polars: Blazingly Fast DataFrame Library., [S.d.]. Disponível em: <https://www.pola.rs/>. Acesso em: 3 fev. 2026
POSIT TEAM. RStudio: Integrated Development Environment for R. Boston, MA: Posit Software, PBC, 2026.
PYTHON SOFTWARE FOUNDATION. Python Language Reference., 5 dez. 2025. Disponível em: <https://www.python.org>
Rmarkdown: Dynamic Documents for R. [S.l.: S.n.].
SHAFRANOVICH, Yakov. Common Format and MIME Type for Comma-Separated Values (CSV) Files. 2005.
TINTO, Vincent. Dropout from Higher Education: A Theoretical Synthesis of Recent Research. Review of Educational Research, v. 45, n. 1, p. 89–125, 1975.
TORVALDS, Linus; HAMANO, Junio C.; GIT CONTRIBUTORS. Git: Distributed Version Control System., 17 nov. 2025. Disponível em: <https://git-scm.com>
Ucimlrepo: Package to Easily Import Datasets from the UC Irvine Machine Learning Repository into Scripts and Notebooks., [S.d.]. Disponível em: <https://github.com/uci-ml-repo/ucimlrepo/tree/main>. Acesso em: 25 jan. 2026
VALENTIM REALINHO, Mónica Vieira Martins. Predict Students’ Dropout and Academic Success. UCI Machine Learning Repository, 2021. Disponível em: <https://archive.ics.uci.edu/dataset/697>. Acesso em: 15 jan. 2026
VANDERPLAS, Jacob et al. Altair: Interactive Statistical Visualizations for Python. Journal of Open Source Software, v. 3, n. 32, p. 1057, 2018.
VIRTANEN, Pauli et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, v. 17, n. 3, p. 261–272, 2 mar. 2020.